Jun 2, 2009 · 1 minute read
islam
about two years ago, i posted about sheikh mohamed’s amazing fajr marketing tshirt. today, i am posting about the latest tshirt in the collection - read, understand, and practice quran.

sheikh is currently in egypt visiting his family and will go and make 3umrah insha’Allah… the bay area really isn’t the same without him. may Allah accept from them and grant him and his family the very best and bring them back safely - ameen.
May 19, 2009 · 2 minute read
codeislam
updated and released the first version of the quran ubiquity plugin! you can go here to install it.
essentially, it contains two commands -
- search-quran - takes a parameter of what to search for and will show the results that match that particular query. hitting enter will bring up the search results page.
- get-ayah - takes a parameter of which ayah (ex 2:2) and an optional parameter of the language/translation you want the ayah in (in english - muhsin khan, for example - note that ubiquity will provide suggestions for these). hitting enter will insert the text into the selection space.
this is uber-useful for muslims imho :p perhaps i will try to provide a screencast later on that shows how to use this for those who are still afraid to try it :)
update - rather than make my own screencast, i’ve decided to record a set of audio instructions on how to use it.
by the way - if you haven’t used ubiquity before, i highly recommend that you watch this video first. it explains what ubiquity is and gives you an idea of what it is useful for. to put it quite simply, ubiquity is amazing. it’s an indispensable tool for your firefox. watch the video :)
and here is the audio tutorial on the quran plugin for ubiquity.
enjoy!
May 19, 2009 · 1 minute read
website
after having pretty much the same theme since the launch of the site, i’ve switched to the excellent iNove wordpress theme. i’ve also cleaned up some links and replaced the previous code highlighter with the very nice syntax highlighter evolved plugin.
Apr 13, 2009 · 2 minute read
code
i recently decided to move my tech tips microblog to identi.ca (the original copy was on jaiku), as i felt it was a little more befitting, actively developed, etc (although jaiku is now open source).
anyway… so i wanted to migrate my posts over - so i wrote a php script to do it (it assumes your jaiku is public and reads it without hassling with oauth).
<?php
$sleepTime = 5;
$jaikuSource = "http://username.jaiku.com/json";
$mode = 'identi.ca';
$baseStatusUrl = 'http://identi.ca/api/statuses/update.json';
// thanks, php-twitter
if ($mode == 'twitter'){
$baseStatusUrl = 'http://twitter.com/statuses/update.json';
$headers = array('Expect:', 'X-Twitter-Client: ',
'X-Twitter-Client-Version: ','X-Twitter-Client-URL: ');
}
$ctr = 0;
$entries = array();
print "destination account username: ";
$username = trim(fgets(STDIN));
print "password: ";
system('stty -echo');
$password = trim(fgets(STDIN));
system('stty echo');
print "\n";
$done = false;
$params = '';
while (true){
$count = 0;
$posts = fetchUrl($jaikuSource . $params);
$json = json_decode($posts, true);
$stream = $json['stream'];
$lastEntry = null;
foreach ($stream as $entry){
if (isset($entry['comment_id'])) continue;
$lastEntry = $entry;
$count++;
$entries[$ctr++] = $entry['title'];
}
if ($count == 0) break;
$lastPostTime = $lastEntry['created_at'];
$ts = split('-', $lastPostTime);
$hd = split('T', $ts[2]);
$min = split('Z', $ts[4]);
$gmtime = gmmktime($hd[1], $ts[3], $min[0], $ts[1], $hd[0], $ts[0]) - 1;
$params = "?offset=$gmtime";
}
for ($i = $ctr-1; $i>=0; $i--){
$params = array('status' => $entries[$i]);
if ($i != ($ctr-1)){
print "sleeping $sleepTime seconds\n";
sleep($sleepTime);
}
twitterApiCall($baseStatusUrl, $params);
print "updated status to: " . $entries[$i] . "\n";
}
function fetchUrl($url){
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$resp = curl_exec($ch);
curl_close($ch);
return $resp;
}
function twitterApiCall($url, $args = null){
global $username, $password, $headers;
// thanks, php-twitter
$ch = curl_init($url);
if (!is_null($args)){
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $args);
}
if ((!empty($username)) && (!empty($password)))
curl_setopt($ch, CURLOPT_USERPWD, $username . ':' . $password);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
if (!empty($headers))
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
$resp = curl_exec($ch);
$info = curl_getinfo($ch);
curl_close($ch);
if ($info['http_code']!=200)
print "error - got an http code of: " . $info['http_code'] . "\n";
}
make sure you edit $baseStatusUrl and $mode as necessary. enjoy!
Mar 20, 2009 · 1 minute read
politics
i usually start my weekdays by listening to the excellent bbc global news podcast. in today’s episode, bbc’s owen bennett-jones interviewed an idf spokeswoman regarding israeli troops’ admission to gaza abuses. i decided to cut it out and provide it here for you to listen to.
audio
is it just me, or do these people seem heartless? anyway, you can download the original podcast here.
Mar 10, 2009 · 1 minute read
random
do you watch anta ambooba in tha3lab al nar? click here for a list of funny, literal arabizations done by my roommate and i.
Mar 8, 2009 · 5 minute read
islamtechnology
a long time ago, when i got my iphone, i realized that it would be nice to be able to read the quran on my phone. what i wanted was a way to read the arabic text on the phone (page by page, not ayah by ayah). anyhow, i’ll outline the solutions i’ve found here along with my preferred solution and how to set it up.
options
-
quran applications in the app store - there are a few in the app store, but only one version of iQuran is free. it shows you the text (ayah by ayah, however), has translations, and audio.
-
images - copy a set of 604 images to your iphone, with each image representing one page of the Quran. then, when you want to read Quran, you load up the photo viewer and read the pages there. you can find these images in many places. here is one example. this is the best solution for reading the Quran in Arabic if you don’t want to jailbreak your phone.
-
pdfs - in my opinion, the best way to read quran on the iphone (if you have a good pdf viewer). you don’t have to hassle with syncing images, nor do you have to deal with 604 files on your phone that you must go through in order to read Quran. also, pdfs tend to be of higher quality than images. this is the solution i recommend if you have or are willing to jailbreak your phone.
since the first solution is straight forward and instructions for the second solution are available on the link above, i will here outline instructions on how to use pdfs.
first, i need to point something out - you technically don’t need to jailbreak your phone to view the quran pdfs on it - you could download one of the apps in the appstore that views pdfs and use it. however, i’ve tried several of the free ones, and was never satisfied with the speed and performance of any of them. the best pdf viewer i found for the iphone is safari itself. so in order to be able to access these pdfs without a connection, you need to have a webserver running on your phone… and that is why you need to jailbreak your phone :)
preview
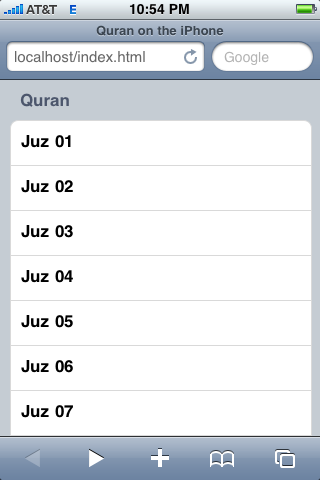
here are three screenshots of how it looks like:
menu
quran text
quran text (wide).
instructions
-
jailbreak your phone. on an older iphone, this is easy (install the newest firmware via itunes, then install and run quickpwn). for the 3g iphone, carefully read the instructions on quickpwn’s website, especially if you want your phone to be unlocked and/or are already using it unlocked.
-
once the phone is jail broken, run cydia. install openssh. then install lighttpd.
-
when you’re on a wifi network, go to your phone’s settings (from the main screen), click on wifi, and choose the network that you are currently connected to by pressing the blue arrow - note down the value of the ip address
-
ssh into your iphone as root - in linux or osx, just open a terminal and run “ssh root@[your phone’s ip address]”. on windows, you can do this by downloading putty. the default password is alpine. keep this terminal open for the next step (recommendation - once you’re in, change your password. type passwd and choose something else besides the default. this is for security purposes).
-
now you can set up lighttpd. download com.http.lighttpd.plist and scp it to /Library/LaunchDaemons (using mac/linux, just do scp com.http.lighttpd.plist root@[iphone’s ip]:/Library/LaunchDaemons). on windows, download winscp, log in (user name root, password is ‘alpine’ unless you’ve changed it in the above step), navigate to /Library/LaunchDaemons, and copy the file over). this file is what will set up lighttpd to start every time the phone is started, and to read the lighttpd.conf from the path below.
-
download lighttpd.conf and scp it to /etc. this is the configuration file for the webserver.
-
download the pdfs and web files. unzip them (you’ll get a web directory), and scp this directory to /var/root/Media (so that the files will be in /var/root/Media/web/*). note that if you change this path, you have to edit lighttpd.conf to reflect wherever you put this.
-
finally, in the terminal you opened in the earlier step, type the following command (this command is what ultimately makes lighttpd start everytime the phone is started):
launchctl load -w /Library/LaunchDaemons/com.http.lighttpd.plist.
and that’s it… you should be good to go! open up safari and navigate to http://localhost/index.html and enjoy!
known issues
-
when transferring data to and from the phone (via ssh or scp), you want to make sure that you’re on wireless. you may also want to make sure the iphone doesn’t “sleep” so that the connection doesn’t drop.
-
sometimes, when you choose a particular file to read, you get a “cannot connect to server” error - it usually disappears and loads the page before you have a chance to click “ok.”
-
if you turn the iphone off while reading a pdf (or go to the main screen, etc), when you come back to safari, sometimes, the page may appear malformed and not allow you to read. to solve this problem, hit back to go to the index and choose a juz’ to reload it.
suggestions/additions/comments are welcome and appreciated.
update - i’ve been using batoul apps’ quranreader at the recommendation of a friend. it’s $1 in the app store, but well worth it.
Mar 4, 2009 · 1 minute read
general
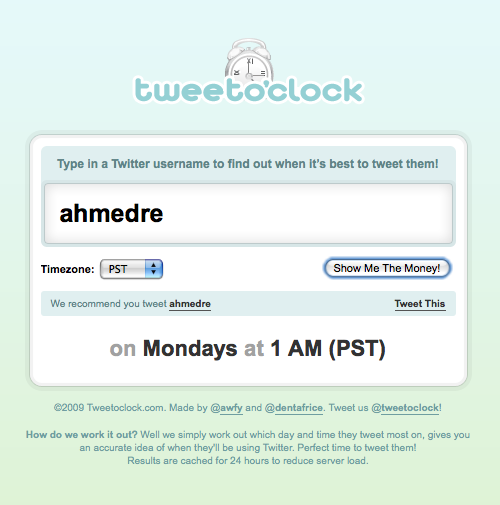
funny. courtesy of tweet o’clock.
Feb 18, 2009 · 1 minute read
codeislam
today, i felt like playing some more with ubiquity, which i had installed for a while now but had not played around with sufficiently. i decided to try to write a simple plugin that will search the quran for a particular set of words. to do this, i felt obliged to expose an api for the alpha version of quranicrealm first, which was good because i needed to do it eventually anyway.
and here’s the mandatory screenshot:
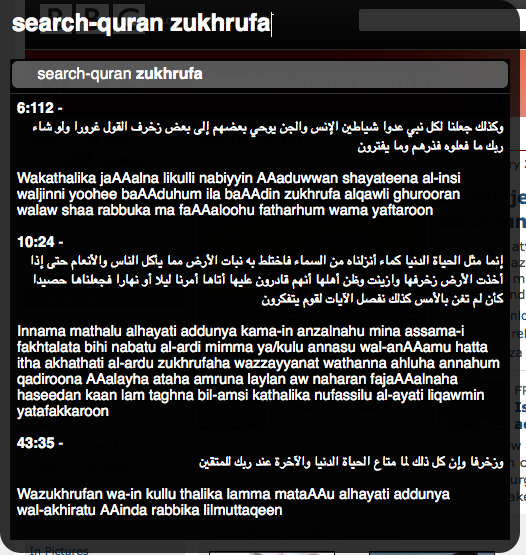
it still needs a lot of work… things i still want to do if i get around to it:
-
add a favicon (for the site and for the plugin)
-
more options (ex, “search english,” or “search transliteration,” etc)
-
replace the current text with a link (or translation). this would be useful in im conversations or while writing blog posts.
-
a “get-ayah” command (to say, “get ayah 1 of sura fatiha in arabic,” for example).
anyway, i’ll post up the code when i’ve added some improvements insha’Allah. if you want it before then, post a comment.
Feb 11, 2009 · 3 minute read
technology
for some (crazy) reason, i decided to try out the g1 after reading gina’s article and finding a good deal on craigslist. the summary is - i think i am going to sell it and keep my iphone :)
thoughts so far:
-
it’s nice to have a keyboard - but something doesn’t feel right about it. i can’t quite put my hands on it yet.
-
no arabic fonts in the browser, and no arabization!! :( iphone doesn’t have it either, but third party solutions (iphone islam) exist that work very well.
-
touch screen isn’t multi touch. also, you have to press with your finger (not the finger tip) - pressing with the finger tip is useless.
-
gmail app totally rocks
-
integration with google (for gmail and calendar) rocks
-
integration with contacts is HORRIBLE. seriously. gmail, as you may know, makes a contact for every person you email. so if you sync your contacts as is with the phone, you’re looking at a ridiculous set of contacts. moreover, if you use the built in google syncing within address book, your address book gets sullied with all these random contacts, duplicates, etc. not very cool. i worked around this by using ab2csv exporter, exporting a csv, and importing it into google contacts under a specific group, then only syncing that group with the phone.
-
one odd caveat - you have to use the supplied usb cable to connect the hone to the pc and be able to mount the micro sd card. using any normal cable you may have (from a camera, for example) will charge the phone, but won’t work for mounting the micro sd card. took me a while to figure this out.
i upgraded the firmware, but haven’t played with google latitude yet (nor with the gps).
i may play with it some more, but at the time being, i am thinking of selling this and sticking with my iphone, as it feels a lot more polished. there are definitely some nice things about it that are missing from the iphone - gears, the fact it runs linux, development seems to be easier (java based), cut and paste, better camera, built in voice dialer, etc. but the iphone feels a lot more polished.
update - “compare everywhere” app rocks - iphone has an equivalent (snaptell, and the amazon app is good too), but it doesn’t scan barcodes. the english to arabic dictionary actually renders proper shaped arabic. apparently, some people have gotten arabic (the font and shaping) to work (though i am not sure if it’s throughout all the apps or not). they haven’t documented it all yet but should soon. i doubt it’ll be to the extent that arabization is done on the iphone, however. battery life is sup-par - went from 100% to 82% in a few minutes by installing and trying a handful of apps.
summary - iphone (even the first gen) still wins.
{kind=link}
{kind=link}
{kind=link}